

Accurate copying of information is essential everywhere – from computer files to the DNA that carries the instructions of life. Modern organisms can make almost exact copies of themselves thanks to biochemical machinery known as enzymes. These enzymes detect and correct mistakes as they arise during DNA copying, like a sophisticated proofreader.
This proofreading means that despite our genome containing billions of base pairs, it can be copied with only a handful of errors each time. If this copying, known as replication, occurred with too many errors, it would be impossible for life to evolve via natural selection, as envisioned by Darwin, because it would be impossible for a cell to bequeath its genome to the next generation.
But long before such biochemical machinery existed, the very first molecules that could copy themselves, or self-replicate, faced a paradox: they must have made lots of errors because no error-correction enzymes had yet evolved. Many errors would have made it nearly impossible to store and transmit the information needed for error-correction machinery, yet accurate replication is required to evolve the machinery that reduces errors.
How, then, could life have escaped this catch-22?
We recently uncovered a simple, non-enzymatic mechanism that could help primitive replicators self-replicate more faithfully. The key is a natural preference for the right ingredients, referred to as selective binding.
We studied a chemical system in which self-replication is driven by the tendency of material to organize together, called self-assembly. In this system, building blocks tend to form rings of different sizes. Researchers in the past found that of those rings, the 6-membered ones spontaneously self-assemble by stacking onto each other to form fibers. Those fibers grow longer, or self-replicate, by converting the building blocks to more 6-membered rings on the fibers’ ends. Long fibers tend to break, exposing more ends that grow and replicate faster. In this way, the fibers create more fibers, as shown in this animation.
When 2 types of building blocks are mixed, rings can be pure or mixed, much like mixing blue and red creates purple. We hypothesized that building blocks might prefer to bind to fibers that match their ‘color,’ because the forces that hold the fibers together also affect how free building blocks interact with the fibers. We further hypothesized that if such binding is indeed selective, this might reduce the number of errors formed during fiber elongation.
To see whether this selective binding occurs, we spun down a solution of fibers and building blocks in a centrifuge, and repeated the experiment 3 times. The fibers precipitated along with any material bound to them. We found that the bound material closely matched the fibers in all of the repeats.
It was impossible to measure the effect of this selective binding on copying accuracy directly, because we can’t ‘turn off’ the binding in the experiment to pinpoint this. Therefore, we built a computer model simulating the dynamical interactions between these molecules, which allowed us to compare the real case – when selective binding is turned on – to a hypothetical case in which binding is turned off. Our model predicted that selective binding produced 50% fewer errors in a system with strong self-replication.
We further proposed that the same mechanism also suppressed the spreading of mistakes. Ordinarily, once an incorrect ring attaches to a fiber’s end, it establishes a new mutated fiber end that attaches further erroneous rings. However, selective binding counters this drift: the material that the fiber attracts is less likely to give rise to more mutant rings, keeping the fiber true to itself. If we think of this process as analogous to driving, then if you stray from the road, the selective binding works to bring you back on the road. Without it, if you divert from the road, you would continue in your new direction.
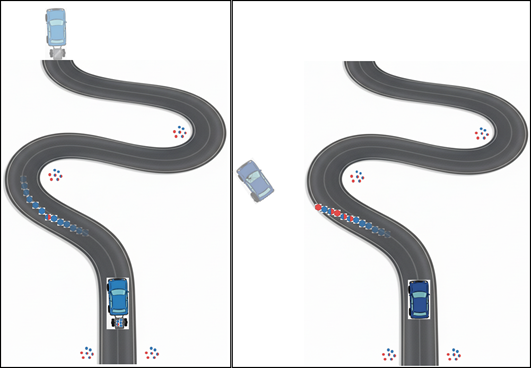
If a self-replicator is like a car, then selective binding keeps the car on the road even if the road winds (left panel). Without it, as soon as the car turns, it can’t change back and goes off-road (right panel). By Omer Markovitch.
We concluded that this mode of error correction is fundamentally different from the way modern enzymes proofread DNA. It requires no new molecular machinery – only the same chemical forces that already drive replication. We suggested that such a mechanism could have allowed early replicators to maintain and gradually improve their replication accuracy as a by-product of evolution, strengthening their interactions and giving evolution the breathing room to invent more elaborate solutions later. In other words, chemistry itself may have provided the first safeguard against information loss, long before biology learned to proofread.
